VOCA
Voice Operated Character Animation
Daniel Cudeiro*, Timo Bolkart*, Cassidy Laidlaw, Anurag Ranjan and Michael J. Black (*authors contributed equally)
Computer Vision and Pattern Recognition (CVPR) 2019, Long Beach, CA
Title
Capture, Learning, and Synthesis of 3D Speaking Styles
Abstract
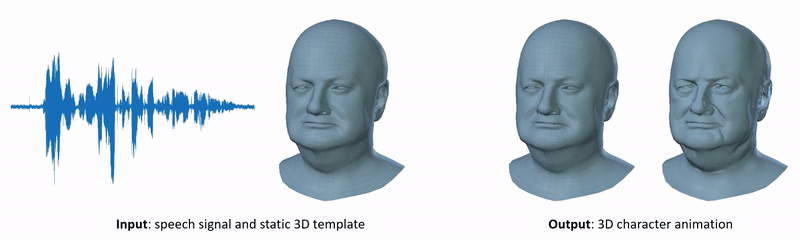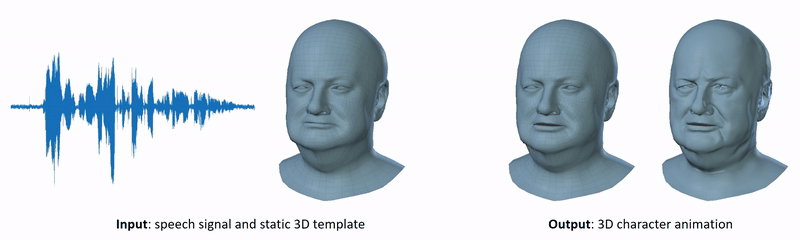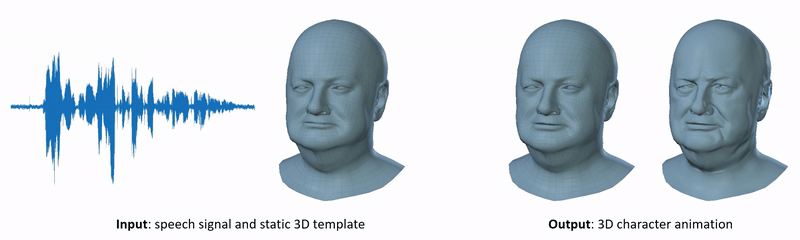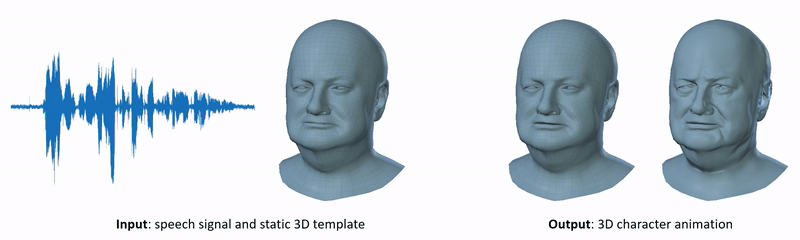
Audio-driven 3D facial animation has been widely explored, but achieving realistic, human-like performance is still unsolved. This is due to the lack of available 3D datasets, models, and standard evaluation metrics. To address this, we introduce a unique 4D face dataset with about 29 minutes of 4D scans captured at 60 fps and synchronized audio from 12 speakers. We then train a neural network on our dataset that factors identity from facial motion. The learned model, VOCA (Voice Operated Character Animation) takes any speech signal as input—even speech in languages other than English—and realistically animates a wide range of adult faces. Conditioning on subject labels during training allows the model to learn a variety of realistic speaking styles. VOCA also provides animator controls to alter speaking style, identity-dependent facial shape, and pose (i.e. head, jaw, and eyeball rotations) during animation. To our knowledge, VOCA is the only realistic 3D facial animation model that is readily applicable to unseen subjects without retargeting. This makes VOCA suitable for tasks like in-game video, virtual reality avatars, or any scenario in which the speaker, speech, or language is not known in advance. We make the dataset and model available for research purposes.
Video
More Information
- Please sign up and agree to the license for access to the data and the model
- pdf preprint
- video
- code
- VOCA Project page at MPI-IS
- For questions, please contact voca@tue.mpg.de
Referencing VOCA
@inproceedings{VOCA2019, title = {Capture, Learning, and Synthesis of {3D} Speaking Styles}, author = {Cudeiro, Daniel and Bolkart, Timo and Laidlaw, Cassidy and Ranjan, Anurag and Black, Michael}, booktitle = {Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)}, pages = {10101--10111}, year = {2019} url = {http://voca.is.tue.mpg.de/} }